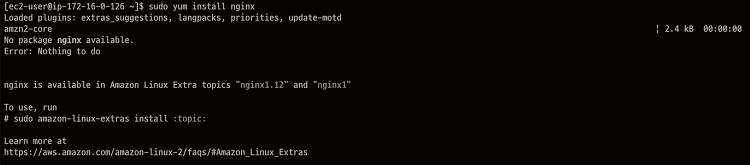
Amazon Linux 2 OS의 EC2에서 nginx 설치하는 방법에 대해서 알아보겠습니다. Amazon Linux 2에서는 yum을 통한 nginx 설치가 지원되지 않습니다. 일반적인 yum 을 통한 설치 시 에러가 발생하는 것을 볼 수 있습니다. sudo yum install nginx yum으로는 nginx 패키지를 찾지 못합니다. To use, run 에 나와있는 amazon-linux-extras install : topic 를 이용하여 nginx 설치를 진행하도록 하겠습니다. amazon-linux-extras list 명령어를 통해 설치할 nginx를 찾아보겠습니다. amazon-linux-extras list | grep nginx 조회된 nginx1에 대해서 설치를 진행해 보겠습니다. ..

자바에서 변수명으로 클래스를 인스턴스화 하는 방법이 있습니다. 방법 1-인수는 없고 생성자만 있는 클래스에만 해당 클래스에 인수가없는 생성자가있는 경우 메서드를 사용하여 Class객체를 가져오고이 메서드를 사용하여 인스턴스를 만들 수 있습니다. Class domainClass = Class.forName("com.femarket.domain." + domainName); Object domain = domainClass.newInstance(); 방법 2 클래스에 인수가없는 생성자가없는 경우에도 작동하는 더 안전한 방법은 클래스 개체를 쿼리하여 해당 Constructor개체 를 가져오고이 개체에 대한 newInstance()메서드를 호출하는 것입니다. Class clazz = Class.forName("..

kube config에서 eks 정보가 있어야해요 워커노드 생성 전에도 접근가능해요 마스터는 어차피 aws에서 관리해서 aws sts get-caller-identity 이걸로 본인 local 컴퓨터에서 access key, secret key 설정했는지 확인하시고 aws eks --region ${region_name} update-kubeconfig --name ${cluster_name} 이걸로 kube config 파일 업데이트하세요 https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/managing-auth.html 클러스터 인증 - Amazon EKS 이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사합니다. 실망시켜 드려 죄송합니다. 잠깐 시간..

자바스크립트에서 현재 날짜 및 시간을 구하기 위해서는 Date 객체를 사용하면 된다. Date 객체를 사용하여 현재의 날짜를 출력하면 YYYY-MM-DD와 같은 형식의 날짜 포맷으로 출력되지 않기 때문에, Date 객체에서 제공하는 추출 함수를 사용하여 날짜 포맷을 변환하는 작업이 추가적으로 필요하다. 현재 날짜, 시간 구하기 var today = new Date(); console.log(today); // 결과 : Sun May 30 2021 15:47:29 GMT+0900 (대한민국 표준시) // 결과 : Sun May 30 2021 15:47:29 GMT+0900 (대한민국 표준시) Date 객체를 사용하여 현재 시스템의 날짜를 가져와서 출력하면, 평상시에 사용하는 날짜 포맷(YYYY-MM-DD ..
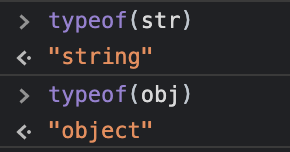
ajax 사용하던 중 한가지 의문이 생겼습니다. 왜 JSON.stringify를 사용하지 않고 데이터를 보내면 왜 스프링 @RequestBody에서 받질 못하는지 말입니다. 그래서 data : {test : "test"} 와 data : JSON.stringify의 타입들을 콘솔로 찍어본 결과 전자는 object이고 후자는 string이였습니다. 여기서 아하! 했습니다. 내가 흔히 말하는 json과 js에서 사용하는 javacscript Object는 다른거구나! 그래서 이거에 대해 글을 찾아본 후 정말 잘 설명해주신 글이 있어서 가져와봤습니다. 이글은 yongseong.log 님의 글입니다. [개발상식] JSON과 JavaScript Object의 차이점 안녕하세요. 김용성입니다.정말 비슷하게 생겨먹은..
var data = {"name":"John Doe"} $.ajax({ type : "post", url : "/test", dataType : "json", //서버에서 받을 데이터 타입 contentType: "application/json; charset=utf-8", //서버로 보내는 데이터 타입 data : JSON.stringify(data), success : function(result) { alert(result.success); }, error: function(e){ alert("fail"); } }); 맨날 까먹어서 제가 보기 위해 씁니다. $.ajax({ type : `http method type`, url : `url`, data : `서버에 전송할 데이터`, contentTy..

CIDR? AWS, GCP, Azure 등 퍼블릭 클라우드 등을 사용할 때 네트워크 설정에서 VPC 및 Subnet 을 생성하여 네트워크를 구성하게 됩니다. 이 때 CIDR(Classless Inter-Domain Routing) 블록을 이용하여 10.10.1.0/24 등과 같이 표시하게 되는데 주니어 개발자 꼬꼬마 시절에는 AWS 콘솔에서 네트워크, 시큐리티그룹 등에서 많이 봐 왔지만 선배들이 알려준 대로 그냥 C클래스일때는 /24, 특정IP만 지정할때는 /32 로 알고 살아왔었고, 아직도 그렇게 알고 있는 사람들이 분명히 있을 것 같아서 간단하지만 정확하게! 포스트를 작성 해 보려 합니다. 참고로 CIDR는 사이더 라고 읽으면 되고, 유툽에서 미국인 개발자가 발음하는걸 들어보니 싸이더 정도로 발음 합..

더미데이터를 삽입하는 프로시저 생성 페이징 테스트와 같이 많은 양의 더미데이터(dummy data)가 필요한 경우, 프로시저를 생성해서 더미데이터를 삽입할 수 있다. Workbench에서 다음과 같이 입력한다. DELIMITER $$ DROP PROCEDURE IF EXISTS loopInsert$$ CREATE PROCEDURE loopInsert() BEGIN DECLARE i INT DEFAULT 1; WHILE i

로드밸런서란? 로드밸런서는 서버에 가해지는 부하(=로드)를 분산(=밸런싱)해주는 장치 또는 기술을 통칭한다. 클라이언트와 서버풀(Server Pool, 분산 네트워크를 구성하는 서버들의 그룹) 사이에 위치하며, 한 대의 서버로 부하가 집중되지 않도록 트래픽을 관리해 각각의 서버가 최적의 퍼포먼스를 보일 수 있도록 한다. 만약 Scale-out의 방식으로 서버를 증설하기로 결정했다면 여러 대의 서버로 트래픽을 균등하게 분산해주는 로드밸런싱이 반드시 필요하다. OSI 7 계층이란? 네트워크 통신 시스템은 크게 일곱 가지의 계층(OSI 7 layers, 개방형 통신을 위한 국제 표준 모델)으로 나뉜다. 각각의 계층(Layer)이 L1/L2/L3‥‥L7에 해당한다. 상위 계층에서 사용되는 장비는 하위 계층의 장..

S3 S3는 AWS가 제공하는 클라우드 스토리지 서비스입니다. 99.999999%라는 높은 내구성이 특징인 스토리지로 미리 스토리지 용량 등을 정의하지 않고 사용할 수 있으며, 데이터 공개 정책, 데이터 암호화, 비용 효율적으로 데이터를 장기 보관하기 위한 라이프사이클 정책 등의 많은 기능을 제공하는 유용한 서비스입니다. S3에서는 스토리지의 기본 단위로 '버킷'이라고 불리는 영역을 생성하고 그 안에 파일을 저장합니다. CloudFront CloudFront는 AWS가 제공하는 콘텐츠 전송 네트워크(Content Delivery Network, CDN) 서비스입니다. CDN은 인터넷에서 웹 콘텐츠, 이미지, 동영상, 애플리케이션 등을 빠르게 전송하기 위한 구조로 되어 있습니다. CloudFront는 전 ..

키바나에서 아래 코드로 요청을 보내면 아래와 같은 응답을 받을 수 있습니다. analyzer는 커스텀 analyzer 사용했습니다. tokenizer는 nori를 사용하였고, filter는 shingle를 사용하였습니다. 이 값을 자바에서 사용하고 싶다면 아래와 같은 코드를 작성해주시면 됩니다. AnalyzeRequest request = AnalyzeRequest.withIndexAnalyzer("st_pdt", "nori_discard_1", pdt.getS_name()); AnalyzeResponse response = client.indices().analyze(request, RequestOptions.DEFAULT); List tokens = response.getTokens(); for(An..

무한 스크롤은 이커머스 관련된 웹이나 앱을 사용하면 쉽게 접할 수 있는 기능입니다. 스크롤의 위치가 어떠한 조건을 충족하게 되면 추가적으로 상품들을 불러옵니다. [JavaScript] 무한 스크롤 시 상품 위치 유지 무한 스크롤 기능을 구현하는데 있어 반드시 병행되어야 할 기능이 있습니다. 바로 무한 스크롤로 렌더링된 상품을 누르고 다시 [뒤로가기]를 했을 시 여전히 그 상품의 위치로 와야 한다는 것 kingofbackend.tistory.com 그럼 어떻게 구현하는지 바로 알아보겠습니다. 무한 스크롤 코드입니다. var stopping = false; var end = false; $(window).scroll(function () { var cst = $(window).scrollTop(); var ..

무한 스크롤 기능을 구현하는데 있어 반드시 병행되어야 할 기능이 있습니다. 바로 무한 스크롤로 렌더링된 상품을 누르고 다시 [뒤로가기]를 했을 시 여전히 그 상품의 위치로 와야 한다는 것입니다. [JavaScript] 무한 스크롤 기능 구현하기 무한 스크롤은 이커머스 관련된 웹이나 앱을 사용하면 쉽게 접할 수 있는 기능입니다. 스크롤의 위치가 어떠한 조건을 충족하게 되면 추가적으로 상품들을 불러옵니다. 그럼 어떻게 구현하는지 kingofbackend.tistory.com 만약, 이 기능이 구현되어 있지 않으면 상품을 누르고 맘에 들지 않아 [뒤로가기]를 눌렀을 때 다시 이 상품이 나왔던 곳까지 스크롤을 내려야 합니다. 오늘의 집, 아이디어스은 어떻게 되어있는 지 한번 보겠습니다. [오늘의 집] 오늘의 집..

function setSessionStorage(key, value){ sessionStorage.setItem(key, value); } function getSessionStorage(key){ return sessionStorage.getItem(key); } function setJSONSessionStorage(key, value){ sessionStorage.setItem(key, JSON.stringify(value)); } function getJSONSessionStorage(key){ return JSON.parse(sessionStorage.getItem(key)); } function removeSessionStorage(key){ sessionStorage.removeItem(ke..

IAM 이란? IAM(AWS Identity and Access Management)은 AWS 리소스에 대한 액세스를 안전하게 제어할 수 있는 웹 서비스입니다. IAM을 사용하여 리소스를 사용하도록 인증 및 권한 부여된 대상을 제어합니다. 물리 데이터 센터를 생각해봅시다. 출입이 허가된 인원들은 출입 카드를 통해 출입하거나, 리스트에 방문 기록을 하고 허가를 받아야 합니다. IAM은 이러한 데이터 센터의 출입 권한을 부여하는 출입카드나, 방문 허가 같은 기능을 가지고 있는 AWS 서비스입니다. 보안 주체가 인증(Authentication)과 권한부여(Authorization)을 받아 리소스에 대한 요청을 승인하는 것이 IAM의 주요 작동 방식입니다. AWS 계정을 처음 생성하는 경우에는 전체 AWS 서비..

이 글은 도커 공부한 흔적을 남기기 위한 글입니다. $ docker run -d -p 8080:80 --name nginx-exposed --restart always nginx 명령어를 실행하면 외부에서 컨테이너 내부에 도달할 수 있습니다. -d(detach) : 백그라운드에서 컨테이너를 실행하는 옵션 -p(publish) : 외부에서 호스트로 보낸 요청을 컨테이너 내부로 전달하는 옵션으로 -p : 형식입니다. * 참고 : 컨테이너 관련 설정은 추후 변경이 불가능합니다. 만약 설정을 바꾸고 싶다면 컨테이너를 새롭게 다시 생성해야 합니다. 이는 도커의 특징으로 컨테이너를 배포 상태로 유지할 수 있게끔 도와줍니다.
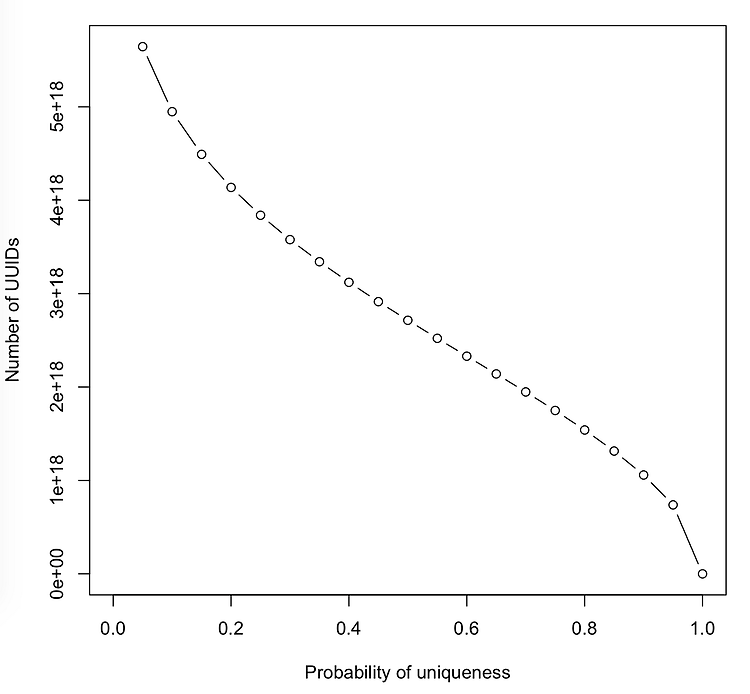
이 글은 koreanhole 님의 글입니다. Intro 최근 UOS공지사항 앱의 백엔드 시스템을 교체하는 작업을 하고 있습니다. 기존 Firebase의 Firestore를 사용하고 있었는데 이번에 새롭게 Nestjs로 서버를 작성하는 중입니다. UOS공지사항의 서버에는 총 3개의 데이터베이스 모델( department, notice, user )이 있습니다. 각 모델의 레코드 마다 고유의 id값을 발급했는데 모두 uuid(v4)로 발급했습니다. uuid를 마구잡이로 발급하게 되면 혹시 나중에 겹치는 uuid가 있지 않을까? UUID 소개 uuid는 범용고유식별자(Universal Unique IDentifier)라고 한다. 네트워크상에 존재하는 개체들을 식별하고 구별하기 위해 개발 주체가 스스로 이름을 ..

웹을 개발하면 한번은 꼭 Cors 문제를 맞닥뜨립니다. 채팅 서버를 aws로 구축하고, 로컬에서 채팅 서버를 이용하여 채팅을 개발하고 있는데 역시나 도메인이 달라 Cors 문제가 발생하였습니다. Node.js 라이브러리중 'Cors'라는 라이브러리가 있지만 Socket.io에서 발생한 문제라서 이걸로는 해결할 수 없습니다. 그래서 구글링을 해본 결과 Socker.io 공식문서에 다행히 잘 설명되어 있습니다. "socket.io": "^4.1.3" 버전 기준입니다. const io = require("socket.io")(server, { cors: { origin: "*", methods: ["GET", "POST"] } }); 위 코드를 server-side에 작성해주시고, client-side에는 아..

이 글은 도커 공부한 흔적을 남기기 위한 글입니다. 이미지는 레지스트리라고 하는 저장소에 모여있습니다. 레지스트리는 도커 허브일수도 있고, 내부에 구축한 레지스트리일 수도 있습니다. 만약 별도의 레지스트리를 명시하지 않으면 도커 허브에서 이미지를 찾습니다. $ docker search nginx 위 명령어로 nginx에 대한 이미지를 찾을 수 있습니다. INDEX : 이미지가 저장된 레지스트리의 이름입니다. NAME : 검색된 이미지 이름입니다. 공식 이미지가 아니라면 '레지스트리 주소/저장소 소유자/ 이미지 형태' 입니다. DESCRIPTION : 이미지에 대한 설명입니다. STARS : 좋아요 갯수입니다. OFFICAL : 이미지에 포함된 애플리케이션, 미들웨어 등을 개발한 업체에서 공식적으로 제공한..

이 글은 김종민(kimjmin@gmail.com)님의 글입니다. 무단 복제/수정을 금합니다. Elasticsearch는 빠른 검색을 위해 검색에 사용될 텀 들을 미리 분리해서 역 인덱스에 저장합니다. 하지만 과학 용어집 검색 같은 특정한 사용 사례에 따라 텀이 아닌 단어의 일부만 가지고도 검색해야 하는 기능이 필요한 경우도 있습니다. RDBMS의 LIKE 검색 처럼 사용하는 wildcard 쿼리나 regexp (정규식) 쿼리도 지원을 하지만, 이런 쿼리들은 메모리 소모가 많고 느리기 때문에 Elasticsearch의 장점을 활용하지 못합니다. 이런 사용을 위해 검색 텀의 일부만 미리 분리해서 저장을 할 수 있는데 이렇게 단어의 일부를 나눈 부위를 NGram 이라고 합니다. 보통은 unigram(유니그램 ..

이 글은 쿠버네티스 공부한 흔적을 남기기 위한 글입니다. $ kubectl get pod pod-name -o yaml 위 명령어는 파드에 대한 yaml 파일 내용을 보여줍니다. $ kubectl get pods pod-name -o yaml > pod.yaml 따라서 위에 명령어를 하게 되면 추후 해당 파드를 생성하기 용이합니다.

이 글은 쿠버네티스 공부한 흔적을 남기기 위한 글입니다. 쿠버네티스에서 파드 자체에 문제가 발생하면 파드를 자동 복구해서 파드가 항상 동작하도록 보장하는 기능이 있습니다. deployment로 생성한 오브젝트와 그냥 파드 오브젝트 2개가 있고, 이를 삭제했다고 했을 시 kubectl get pods 명령어로오브젝트들을 확인해보면 deployment 오브젝트만 살아있습니다. deployment 안에 있는 replicat셋에 의해서 파드의 갯수를 유지하려고 하기 때문에 deployment로 생성한 파드들은 삭제되도 다시 생성이 됩니다. age를 봐도 다시 생성된걸 알 수 있습니다. 하지만 그냥 파드는 이를 관리하는 컨트롤러가 없기 때문에 자동복구가 보장되지 않습니다. *참고 : 컨트롤러는 쿠버네티스 클러스터..

이 글은 쿠버네티스 공부한 흔적을 남기기 위한 글입니다. 배포한 파드에 접근 하기 위해서는 $ kubectl exec -it nginx-pod -- /bin/bash 명령어를 입력해주어야 합니다. 아래 2개의 명령어를 예제로 들어보겠습니다. $ kubectl exec -it nginx-pod ls -l /run $ kubectl exec -it nginx-pod -- ls -l /run 첫번째 명령어는 -l 옵션을 exec의 옵션으로 인식하기 때문에 에러가 발생합니다. 따라서 두번째 명령어를 사용하게 된다면 의도한대로 /run의 권한을 볼 수 있습니다. 이처럼 굳이 필요하지 않아도 exec를 사용할 때 명시적으로 '--'를 사용하면 에러를 줄일 수 있습니다.

distro-stable version 설치 (apt) 간단하게 apt를 이용해 설치해보겠습니다. $ sudo apt update $ sudo apt install nodejs $ sudo apt install npm 그런데 버전이 너무 낮습니다. 최신 버전을 받기 위해 PPA(Personal package archive)를 사용해보겠습니다. PPA로 설치 NodeSource에 의해 관리되는 PPA에서 좀 더 최신 버전을 받아보겠습니다. 게시물 작성 일자 기준 LTS 버전은 12.18.3, Latest 버전은 14.7.0인데 Latest인 14버전으로 설치해보겠습니다. $ curl -sL https://deb.nodesource.com/setup_14.x -o nodesource_14_setup.sh 설..

이 글은 쿠버네티스 공부한 흔적을 남기기 위한 글입니다. 기본 오브젝트로 쿠버네티스 클러스터를 구성할 수 있지만 한계가 있습니다. 이러한 한계를 극복하고자 기본 오브젝트 외 다양한 오브젝트들이 존재하는데 이번엔 디플로이먼트 오브젝트에 대해 알아보겠습니다. 디플로이먼트 디플로이먼트는 한마디로 파드 + 레플리카셋입니다. * 참고 : 레플리카셋은 파드의 수를 보장해주는 오브젝트입니다. 쿠버네티스 클러스터에서의 API 서버와 컨트롤러 매니저는 단순히 파드의 감시가 아닌 디플로이먼트처럼 다양한 오브젝트를 감시합니다. 디플로이먼트를 생성할 때 사용하는 명령어로는 기본적으로 create, apply 을 사용합니다. 디플로이먼트로 생성한 파드를 늘리고 싶으면 scale 명령어를 다시 쳐야하지만 yaml을 사용하여 디플..

이 글은 쿠버네티스 공부한 흔적을 남기기 위한 글입니다. 오브젝트란? 파드와 디플로이먼트는 스펙과 상태값을 가지는 데 이러한 파드와 디플로이먼트를 개별 속성을 포함해 부르는 단위가 오브젝트입니다. * 참고 : 파드도 오브젝트이다. 기본 오브젝트 기본 오브젝트의 종류로는 파드, 네임스페이스, 볼륨, 서비스입니다. 파드 쿠버네티스에서 실행되는 최소단위입니다. 독립적인 공간과 IP를 가지며, 하나 이상의 컨테이너를 가지지만 보통 1 파드 1 컨테이너 구조입니다. 네임스페이스 쿠버네티스 클러스터에서 사용되는 리소스들을 구분해 관리하는 그룹입니다. 볼륨 기본적으로 파드는 어디에 영속되는 개념이 아니지만 파드가 사라지더라도 보존 가능하게 해주는 오브젝트입니다. * 참고 : 파드는 언제나 죽을수 있는 오브젝트입니다...

이 글은 쿠버네티스 공부한 흔적을 남기기 위한 글입니다. 오브젝트를 생성할 때 명령어만으론 한계가 있어 yaml에 스펙을 작성 후 생성합니다. 작성한 yaml 파일 기준으로 run, create, apply로 오브젝트를 생성하는데 create, apply을 주로 사용합니다. run과 create 비교 run은 파드 1개만 생성하고 관리해줍니다. create는 그룹 내 파드 1개를 생성하고 관리해줍니다. run으로 생성한 파드는 초코파이1개이고, create로 생성한 파드는 초코파이 박스 안에 있는 초코파이1개입니다. create과 apply 비교 오브젝트가 디플로이먼트 일 경우 replicas 를 지정해주어서 파드의 갯수를 보장받을 수 있습니다. 만약 create를 이용하여 디플로이먼트 생성했을 경우 y..

쿠키(Cookie) 저장하기 var setCookie = function(name, value, exp) { var date = new Date(); date.setTime(date.getTime() + exp*24*60*60*1000); document.cookie = name + '=' + value + ';expires=' + date.toUTCString() + ';path=/'; }; // setCookie(변수이름, 변수값, 기간); setCookie("expend", "true", 1); 쿠키(Cookie) 가져오기 var getCookie = function(name) { var value = document.cookie.match('(^|;) ?' + name + '=([^;]*)(;|$..
